
















Data availability plays a central role in any machine learning setup, especially since the rise of deep learning. While usually input data is available in abundance, reference data to train and evaluate corresponding approaches is often scarce due to the high costs of obtaining it. While this is not limited to remote sensing, it is of particular importance in Earth observation applications. Semi-supervised learning is one approach to mitigate this challenge and leverage the large amount of available input data while only relying on a small annotated training set.
The semi-supervised learning challenge of the 2022 IEEE GRSS Data Fusion Contest, organized by the Image Analysis and Data Fusion Technical Committee (IADF TC) of the IEEE Geoscience and Remote Sensing Society (GRSS), Université Bretagne-Sud, ONERA, and ESA Φ-lab aims to promote research in automatic land cover classification from only partially annotated training data consisting of VHR RGB imagery.
To this aim, the DFC22 is based on MiniFrance, a dataset for semi-supervised semantic segmentation. As in real life Earth observation applications, MiniFrance comprises both labeled and unlabeled imagery for developing and training algorithms. It consists of a variety of classes at several locations with different appearances which allows to push the generalization capacities of the models.
MiniFrance proposes new challenges for semi-supervised learning in Earth observation, due to its unprecedented properties:
Designed for semi-supervised semantic segmentation. To our knowledge, this is the first dataset specifically designed for semi-supervised learning strategies. The training set includes labeled and unlabeled images from two and six cities, respectively.
With such proportions, it fosters the development of new methods able to leverage unlabeled examples. These methods are likely to be easily transferred to lifelike scenarios and to have better generalization properties by design.
Geographic domain adaptation. MiniFrance includes aerial images of 16 conurbations and their surroundings from different regions with various climates and landscapes (Mediterranean, oceanic and mountainous) in France. Introducing various locations leads to various appearances for the same class (buildings look different, vegetation is not the same and so on). Moreover, it combines urban centers, rural areas, and large forest scenes. Hence, it requires methods able to cope with domain adaptation issues.
High semantic level of classes. MiniFrance considers 14 land-use classes with high-level semantics. Rather than looking for classes at an object level (cars, buildings, trees, etc), they require algorithms able to understand variety and spatial relationships, as for example groups of houses and buildings to identify as an “urban area”.
The MiniFrance-DFC22 (MF-DFC22) dataset extends and modifies the MiniFrance dataset for training semi-supervised semantic segmentation models for land use/land cover mapping. The multimodal MF-DFC22 contains aerial images, elevation model, and land use/land cover maps corresponding to 19 conurbations and their surroundings from different regions in France. It includes urban and countryside scenes: residential areas, industrial and commercial zones but also fields, forests, sea-shore, and low mountains. It gathers data from three sources:
- Open data VHR aerial images from the French National Institute of Geographical and Forest Information (IGN) BD ORTHO database[1]. They are provided as 8-bit RGB tiles of size ~2,000px x ~2,000px at a resolution of 50cm/px, namely 1 km2 per tile. Images included in this dataset were acquired between 2012 and 2014.
- Open data Digital Elevation Model (DEM) tiles from the IGN RGE ALTI database. DEM data gives a representation of the bare ground (bare earth) topographic surface of the Earth. They are provided as 32-bit float rasters of size ~1,000px x ~1,000px at a spatial resolution of 100cm/px, i.e. also 1 km2 per tile. The altitude is given in meters, with sub-metric precision in most locations. This database is regularly updated so images included in the dataset were acquired between 2019 and 2020.
- Labeled class-reference from the UrbanAtlas 2012 database. 14 land-use classes are considered, corresponding to the second level of the semantic hierarchy defined by UrbanAtlas. Original data are openly available as vector images at the European Copernicus program website and were used to create raster maps that geographically match the VHR tiles from BD ORTHO. They are provided as integer rasters with index labels (0 to 15 – 8 and 9 being UrbanAtlas classes which do not appear in the regions considered) of size ~2,000px x ~2,000px at a resolution of 50cm/px, namely 1 km2 per tile.
Track SLM: Semi-supervised Land Cover Mapping
The DFC22 aims to promote innovation in automatic land cover classification, as well as to provide objective and fair comparisons among methods. The ranking in Track SLM is based on quantitative accuracy parameters computed with respect to undisclosed test samples. Participants will be given a limited time to submit their land cover maps after the competition starts.
The contest of this track will consist of two phases:
Phase 1: Participants are provided with training data and additional validation images (without corresponding labels) to train and validate their algorithms. Participants can submit land cover maps for the validation set to the Codalab competition website (codalab.lisn.upsaclay.fr/competitions/880) to get feedback on the performance. The performance of the last submission from each account will be displayed on the leaderboard. In parallel, participants submit a short description of the approach used to be eligible to enter Phase 2.
Phase 2: Participants receive the test data set (without the corresponding reference data) and submit their land cover mapswithin five days from the release of the test data set. After evaluation of the results, three winners are announced.Following this, they will have one month to write their manuscript that will be included in the IGARSS 2022 proceedings. Manuscripts are 4-page IEEE-style formatted. Each manuscript describes the addressed problem, the proposed method, and the experimental results.
Submissions to the evaluation server shall be made as integer rasters where each pixel contains the class ID, similar to the provided reference data of the training set. These estimates are compared against the reference data via the mean Intersection over Union score. During the development phase, the MF-DFC22 land cover data will serve as reference. However, during the test phase we will use annotations that have been carefully manually created from the test data and are even more precise.
It should also be noted that the location of train and validation data is known (through file naming and metadata in the tif files). However, this information will not be available for the test data. Thus, participants should not explicitly rely on it.
Track BNI: Brave New Ideas
Due to the uniqueness of the DFC22, a second track is created which allows to explore new ideas more freely without being limited to land cover classification. In this track, all is possible and all is allowed, as long as it is novel and exciting. Even if it would be possible, results of different submissions will not be compared to each other – neither qualitatively nor quantitatively.
The ranking in Track BNI is based on the evaluation of a methodological description of the approach by the DFC committee. Participants will receive the same data as described above for Track SLM. They are free to submit their results to the Codalab competition website or even join the Track SLM in parallel if the “new idea” fits into its scope. However, evaluation will be based on the submitted description only. The short descriptions should be 2-4-page IEEE-style formatted, i.e. follow the IGARSS22 paper template.
Calendar
- January 3: Contest opening: release of training and validation data
- January 4: Evaluation server begins accepting submissions for validation data set
- February 28: Short description of the approach. Track SLM 1-2 pages; Track BNI 2-4 pages
- March 7: Release of test data; evaluation server begins accepting test submissions
- March 11: Evaluation server stops accepting submissions
- March 11: Updated and final description for Track BNI
- March 25: Winner announcement
- April 23: Internal deadline for papers, DFC Committee review process
- May 31: IGARSS full paper deadline.
The Data
The proposed dataset consists of very-high-resolution imagery, DEM information and semantic maps corresponding to 19 conurbations and their surroundings, spanning over different regions in France. Data are split in three partitions for training, validation and testing, with the particularity that the training partition obeys to semi-supervised learning conditions.
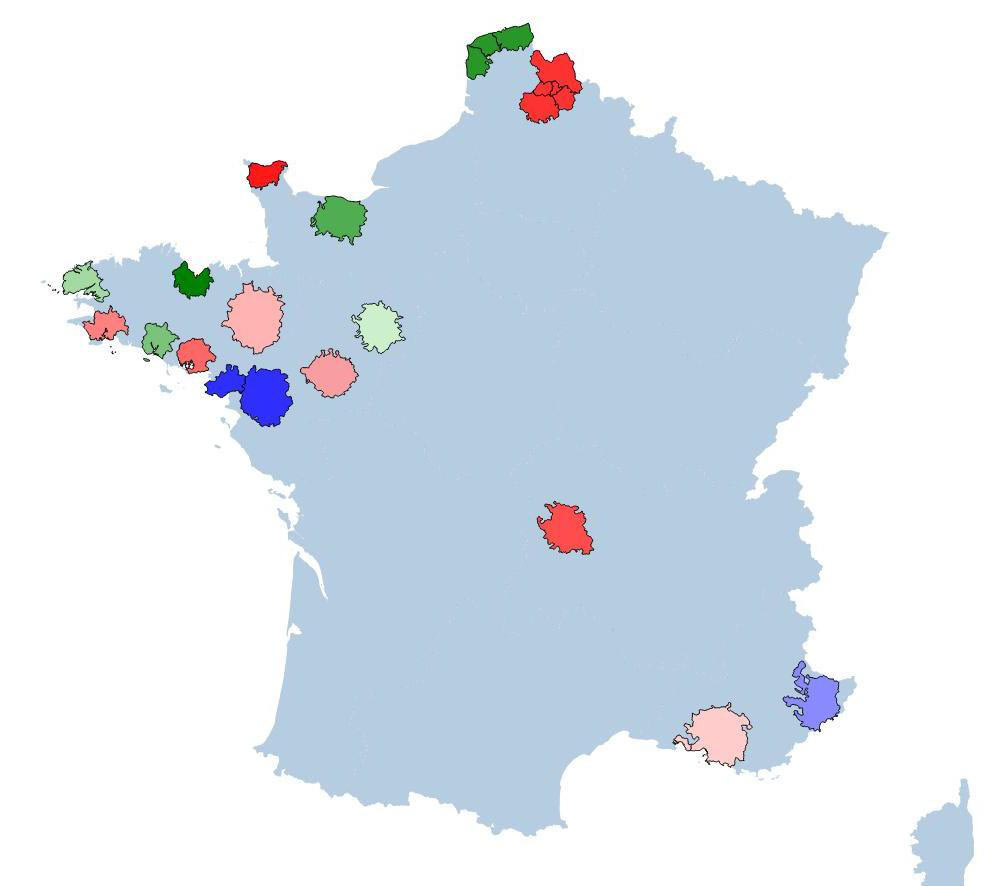
The training partition (labeled + unlabeled, blue and green shades in Fig. 1, respectively), contains a total of 1915 tiles. The largest area corresponds to Nantes/Saint-Nazaire with 433 tiles, while the smallest area is Lorient with only 120 tiles. Data is provided with georeference information.
The validation partition contains eight georeferenced areas with RGB images and DEM information (red shaded areas in Fig.1). This partition contains 2066 tiles. Largest area is Lille/Arras/Lens/Douai/Henin including 407 tiles, smallest one is Cherbourg with 113 tiles.
The test partition consists of three areas without georeference information and contains RGB images and DEM information only. This partition includes 1035 tiles.
The semantic segmentation problem posed by MF-DFC22 (see Fig. 2 for several examples) considers 14 classes. These are defined by the second level of hierarchy of UrbanAtlas, with a total of 12 land use / land cover classes (urban fabric, industrial, mine & construction sites, pastures, forests, etc.), plus a no-data label (0) and clouds & shadows (15). MF-DFC22 raises a class-imbalance challenge, with less represented classes (mine, dump & construction sites, permanent crops, open spaces with little or no vegetation, wetlands and water) and majority classes (arable land and pastures). Note that 2 classes from the original UrbanAtlas nomenclature are not present in the dataset: 8 (mixed cultivation patterns) and 9 (orchards).

The goal is to identify 12 different land cover classes based on the provided image data. Table 1 below provides class names, the color scheme, as well as approximate class frequencies over the training set. All figures during the competition should follow the specified color scheme.
| UrbanAtlas Class Name | Aproximate Class Frequency | |
| 0 | No information | 23.0% |
| 1 | Urban fabric | 6.9% |
| 2 | Industrial, commercial, public, military, private and transport units | 4.3% |
| 3 | Mine, dump and construction sites | 0.3% |
| 4 | Artificial non-agricultural vegetated areas | 0.9% |
| 5 | Arable land (annual crops) | 8.0% |
| 6 | Permanent crops | 1.3% |
| 7 | Pastures | 23.5% |
| 8 | Complex and mixed cultivation patterns | 0% |
| 9 | Orchards at the fringe of urban classes | 0% |
| 10 | Forests | 18.7% |
| 11 | Herbaceous vegetation associations | 7.8% |
| 12 | Open spaces with little or no vegetation | 2.2% |
| 13 | Wetlands | 2.0% |
| 14 | Water | 1.0% |
| 15 | Clouds and shadows | 0.0% |
Table 1: Color scheme and approximate frequencies of the MF-DFC22 data set.
Note that a considerable part of the training data is not labeled and thus contributes to the semi-supervised learning setup. Pixels annotated in the reference data of the val and test part with either 0 or 15 will not contribute to scoring. Classes 8 and 9 are not present in any of the data splits (neither train, nor val, not test data). Note, that the class frequencies will vary slightly in the validation and test splits. Furthermore, temporal differences as well as the way how the semantic maps of the UrbanAtlas are generated cause a considerable amount of label noise. This will be present for the training as well as for evaluation during the development phase (based on the validation data). However, the evaluation during the final phase on the test data wont use the UrbanAtlas but more precise annotations.
Submission Format
Participants will submit predictions of semantic maps. Each pixel corresponds to one of the class IDs specified above (similar to the reference data of the training set).
- Predicted images should be uploaded as follows:
- The predictions for a particular tile should be encoded as a TIFF with the Byte (uint8) data type, match the dimensions of the corresponding BD ORTHO image and contain values between 1 and 14 (inclusive).
- Each tile of predictions should be compressed in place (e.g., using the GDAL library), and all TIFF files should be submitted in a compressed zip archive. This is a particularly important point, as the competition website will not accept submissions of over 300MB and uncompressed submissions will likely surpass this limit.
- Name the TIFF files _prediction.tif, where is the filename of the corresponding tile in the BD ORTHO database.
- Predictions for each concurbations should be placed into corresponding folders with names identical to the folders of the validation/test data.
- Please make sure that all TIFF files are readable by Pillow.
Baseline
A baseline that shows how to use the DFC22 data to train models, make submissions, etc can be found here. See also the Documentation page for the dataset.
This baseline uses TorchGeo, PyTorch Lightning, and Segmentation Models PyTorch to train a U-Net with a ResNet-18 backbone and a loss function of Focal + Dice loss to perform semantic segmentation on the DFC2022 dataset. Masks for the holdout set are then predicted and zipped to be submitted. Note that the this supervised baseline is only trained on the labeled train set containing imagery from the Nice and Nantes Saint-Nazaire regions and results in a mIoU of 0.1278 on the heldout validation set. Participants utilizing semi-supervised learning techniques should seek improve upon this score.
Results, Awards, and Prizes
The following four teams will be declared as winners:
- The first, second, and third teams in Track SLM
- The first-ranked team in Track BNI
The authors of the four winning submissions will:
- Present their approach in an invited session dedicated to the DFC22 at IGARSS 2022
- Publish their manuscripts in the proceedings of IGARSS 2022
- Be awarded IEEE Certificates of Recognition.
The authors
- of the 1st to 3rd-ranked teams in SLM will receive MS Azure credits of $8k, $5k, and $2k, respectively.
- of the first team in BNI will receive MS Azure credits of $5k
The authors of the first and second-ranked teams in SLM and first-ranked in BNI will:
- Co-author a journal paper which will summarize the outcome of the DFC22 and will be submitted with open access to IEEE JSTARS.
Top-ranked teams will be awarded during IGARSS 2022, Kuala Lumpur, Malaysia in July 2022. The costs for open-access JSTARS publication will be supported by the GRSS. The winners of the competition will receive a total of $20k in Azure cloud credits as prizes, courtesy of Microsoft’s AI for Earth program.
The Rules of the Game
- The dataset can be openly downloaded at ieee-dataport.org/competitions/data-fusion-contest-2022-dfc2022.
- Validation and test data can be requested by registering for the Contest at IEEE DataPort.
- To enter the contest, participants must read and accept the Contest Terms and Conditions.
- Participants of the contest are intended to submit land cover maps following the classification scheme in raster format (similar to the tif files of the training set).
- For sake of visual comparability of the results, all land cover maps shown in figures or illustrations should follow the color palette of the classification scheme detailed in the class table above.
- The classification results will be submitted to the Codalab competition website (codalab.lisn.upsaclay.fr/competitions/880) for evaluation.
- Ranking between the participants will be based on the mean intersection-over-union (mIoU) averaged over these semantic classes
- The maximum number of trials of one team is ten in the test phase.
- Deadline for classification result submission (Track SLM) and final description (Track BNI) is March 11, 2022, 23:59 UTC–12 hours (e.g., March 11, 2022, 7:59 in New York City, 13:59 in Paris, or 19:59 in Beijing). The submission server will be opened from March 7, 2021.
- Each team in Track SLM needs to submit a short paper of 1–2 pages clarifying the used approach, the team members, their Codalab accounts, and one Codalab account to be used for the test phase by February 28, 2021. Please send the paper to iadf_chairs@grss-ieee.org using the IGARSS paper template.
- Each team in Track BNI needs to submit a short paper of at least 2 pages clarifying the used approach, the team members, their Codalab accounts (if applicable), and one Codalab account to be used for the test phase (if applicable) by February 28, 2021. Please send the paper to iadf_chairs@grss-ieee.org using the IGARSS paper template.
- Important: Only team members explicitly stated on these documents will be considered for the next steps of the DFC, i.e. being eligible to be awarded as winners and joining the author list of the respective potential publications (IGARSS22 and JSTARS articles). Furthermore, no overlap among teams is allowed, i.e. one person can only be a member of one team. Adding more team members after the end of the development phase, i.e. after submitting these documents is not possible.
- For the 3+1 winners, the internal deadline for full paper submission is April 23, 2022, 23:59 UTC–12 hours (e.g., April 23, 2022, 7:59 in New York City, 13:59 in Paris, or 19:59 in Beijing). IGARSS Full paper submission is May 31, 2022.
- Persons directly involved in the organization of the contest, i.e. the (co-)chairs of IADF as well as the co-organizers are not allowed to enter the contest. Please note that IADF WG leads can enter the contest. They have been actively excluded from all information concerning the content of the DFC to ensure a fair competition.
Failure to follow any of these rules will automatically make the submission invalid, resulting in the manuscript not being evaluated and disqualification from the prize award.
Participants to the Contest are requested not to submit an extended abstract to IGARSS 2022 by the corresponding conference deadline in January 2022. Only contest winners (participants corresponding to the best-ranking submissions) will submit a 4-page paper describing their approach to the Contest by April 23, 2022. The received manuscripts will be reviewed by the Award Committee of the Contest, and reviews sent to the winners. Then winners will submit the final version of the 4 full-paper to IGARSS Data Fusion Contest Invited Session by May 31, 2022, for inclusion in the IGARSS Technical Program and Proceedings.
Acknowledgments
The IADF TC chairs would like to thank Université Bretagne-Sud, ONERA, and ESA Φ-lab for providing the data and the IEEE GRSS for continuously supporting the annual Data Fusion Contest through funding and resources.
The winners of the competition will receive a total of $20k in Azure cloud credits as prizes, courtesy of Microsoft’s AI for Earth program.

Terms and Conditions
Participants of this challenge acknowledge that they have read and agree to the following Contest Terms and Conditions:
- In any scientific publication using the data, the data shall be referenced as follows: “[REF. NO.] 2022 IEEE GRSS Data Fusion Contest. Online: www.grss-ieee.org/technical-committees/image-analysis-and-data-fusion/”.
- Any scientific publication using the data shall include a section “Acknowledgement”. This section shall include the following sentence: “The authors would like to thank the IEEE GRSS Image Analysis and Data Fusion Technical Committee, Université Bretagne-Sud, ONERA, and ESA Φ-lab for organizing the Data Fusion Contest”.
- [Castillo-Navarro et al., 2021] Castillo-Navarro, J., Le Saux, B., Boulch, A. and Lefèvre, S.. Semi-supervised semantic segmentation in Earth Observation: the MiniFrance suite, dataset analysis and multi-task network study. Mach Learn (2021).doi.org/10.1007/s10994-020-05943-y
- [Hänsch et al., 2019] Hänsch, R.; Persello, C.; Vivone, G.; Castillo Navarro, J.; Boulch, A.; Lefèvre, S.; Le Saux, B. : 2022 IEEE GRSS Data Fusion Contest: Semi-Supervised Learning [Technical Committees], IEEE Geoscience and Remote Sensing Magazine, March 2022
The images in this dataset are released under IGN’s “licence ouverte”. More information can be found at www.ign.fr/institut/activites/lign-lopen-data
The maps used to generate the labels in this dataset come from the Copernicus program, and as such are subject to the terms described here: land.copernicus.eu/local/urban-atlas/urban-atlas-2012?tab=metadata“